Appearance
从多进程、多线程到协程
为什么需要并发编程
与并发相对的是串行,即代码按照顺序一行一行执行,当遇到某个耗时的 IO 操作时,比如发送邮件、查询数据库等,要等到该 IO 操作完成后才能继续执行下一行代码,这在一些要求高并发高性能的业务场景中,显然是不合适的。
从整个操作系统层面来说,多个任务是可以并发执行的,因为 CPU 本身通常是多核的,而且即使是单核 CPU,也可以通过时间分片的方式在多个进程/线程之间切换执行,从用户角度来说,就好像它们在「同时执行」一样,比如说,当程序执行到 IO 操作时,我们可以挂起这个任务,把 CPU 时间片出让给其他任务,然后当这个 IO 操作完成时,通知 CPU 恢复后续代码的执行,实际上 CPU 大部分时间都是在做这种调度。
所以并发编程可以最大限度榨取 CPU 的价值,提高程序的执行效率和性能。
这里面有两个概念容易混淆,即并发(Concurrency)和并行(Parallelism):
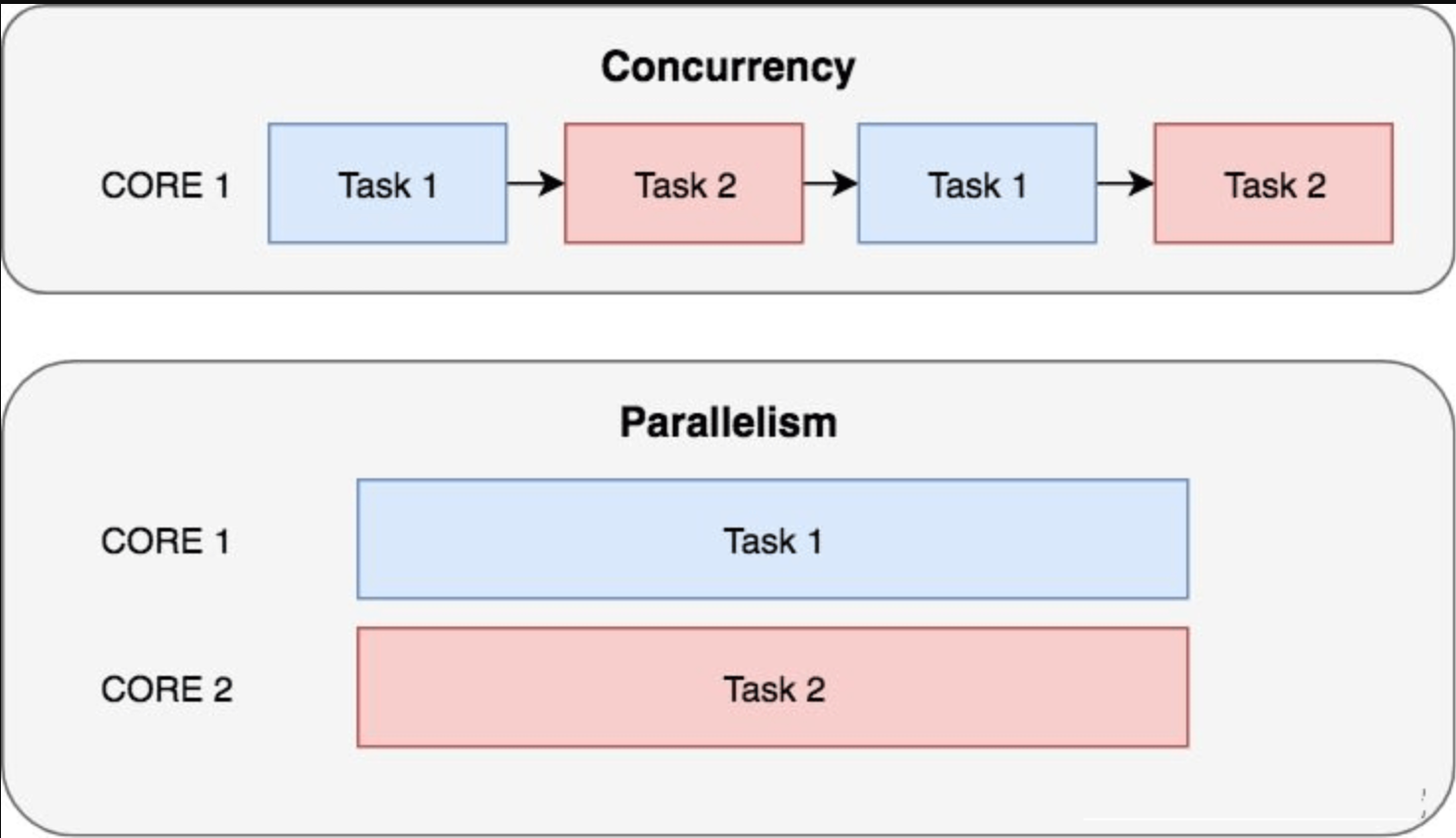
并行侧重于通过CPU多核能力同时处理多个任务,每个任务分配给单独处理器执行,同一时间点,任务是同时执行的;而并发则侧重于在单核CPU中,通过CPU时间分片实现任务的交替执行,由于CPU上下文切换很快,给用户的感觉和多个任务同时执行没有什么区别。
所以并行才是真正物理意义上的多任务同时执行,并发只是逻辑意义上的多任务同时执行,不过并行需要多核支持,并且不同内核之间资源不共享,会导致系统资源开销很大,任务之间的通信非常困难,并发可以在单核内完成,系统开销更小,任务间通信更方便,因此目前主流的并发编程都是沿着这个方向演进。
Go 语言的并发编程也是基于并发实现的,而非并行。
并发编程的常见实现
目前,主流的并发编程实现有以下几种方式:
- 多进程。多进程是在操作系统层面进行并发的基本模式,同时也是开销最大的模式。在 Linux 平台上,很多工具正是采用这种模式在工作,比如 PHP-FPM,它会有专门的主进程负责网络端口的监听和连接管理,还会有多个工作进程负责具体的请求处理。这种方法的好处在于简单、进程间互不影响,坏处在于系统开销大,因为所有的进程都是由内核管理的,而且不同进程的数据也是相互隔离的。
- 多线程。多线程在大部分操作系统上都属于系统层面的并发模式,也是我们使用最多的最有效的一种模式。目前,常见的几乎所有工具都会使用这种模式,线程比进程轻量级,线程间可以共享数据,开销要比多进程小很多,但是依旧比较大,且在高并发模式下,效率会有影响,比如 C10K 问题,即支持 1 万个并发连接需要一万个线程,这不但对系统资源有较高的要求,还对 CPU 管理这些线程带来巨大负担。
- 基于回调的非阻塞/异步 IO。为了解决 C10K 问题,在很多高并发服务器开发实践中,都会通过事件驱动的方式使用异步 IO,在这种模式下,一个线程可以维护多个 Socket 连接,从而降低系统开销,保持服务器的持续运转,它目前在 Node.js 中得到了很好的实践,实际上 Nginx 也使用了这种方式。但是使用这种模式,编程比多线程要复杂,通常需要借助 Linux 底层的库函数来实现。
- 协程。协程(Coroutine)本质上是一种用户态线程,你可以把它看作轻量级的线程,不需要操作系统来进行抢占式调度,系统开销极小,可以有效提高线程的任务并发性,避免多线程的缺点。使用协程的优点是编程简单,结构清晰;缺点是需要语言级别的支持,如果不支持,则需要用户在程序中自行实现相应的调度器。目前,原生支持协程的语言还很少,Go 语言就是其中这一,Go 语言中的协程称作「goroutine」,并且使用语言名称本身
go做为协程的关键字,足见其在 Go 语言中的举足轻重。PHP 的 Swoole 扩展也是参考了 Go 协程的实现将其搬到 PHP 中。
接下来我们先诠释一下传统并发模型的缺陷,之后再讲解 goroutine 并发模型是如何解决这些缺陷的。由于多进程比较消耗系统资源,且进程间数据隔离,CPU 切换成本高,因此,传统并发编程多以多线程为主,比如 Java 就是这么做的。下面我们重点探讨多线程与协程的对比。
在串行编程中,事务具有确定性,比如我们想好了123,然后按照这个顺序来编写代码,代码会严格按照这个设定的顺序执行,即使在某一个步骤阻塞了,也会一直等待阻塞代码执行完毕,再去执行下一步的代码。
多线程并发模式在这种确定性中引入了不确定性,比如我们原先设定的123,第2步是一个耗时操作,我们启动了一个新的线程来处理,这个时候就存在了两个并发的线程,即原来的主线程和第2步启动的新线程,主线程继续往后执行,第2、3步的代码并发执行,这个时候不确定性就来了,我们不知道主线程执行完毕的时候,新线程是否执行完毕了,如果主线程执行完毕退出应用,可能导致新线程的中断,或者我们在第3步的时候依赖第2步的某个返回结果,我们不知道啥时候能够返回这个结果,如果第2、3步有相互依赖的变量,甚至可能出现死锁,以及我们如何在主线程中获取新线程的异常和错误信息并进行相应的处理,等等,这种不确定性给程序的行为带来了意外和危害,也让程序变得不可控。

不同的线程好比平行时空,我们需要通过线程间通信来告知不同线程目前各自运行的状态和结果,以便使程序可控,线程之间通信可以通过共享内存的方式,即在不同线程中操作的是同一个内存地址上存储的值。为了保证共享内存的有效性,需要采取很多措施,比如加锁来避免死锁或资源竞争,还是以上面的主线程和新线程为例,如果我们在第1步获取了一个中间结果,第2步和第3步都要对这个中间结果进行操作,如果不加锁保证操作的原子性,很有可能产生脏数据。诸如此类的问题在生产环境极有可能造成重大故障甚至事故,而且不易察觉和调试。
我们可以将线程加共享内存的方式称为「共享内存系统」。为了解决共享内存系统存在的问题,计算机科学家们又提出了「消息传递系统」,所谓「消息传递系统」指的是将线程间共享状态的各种操作都封装在线程之间传递的消息中,这通常要求发送消息时对状态进行复制,并且在消息传递的边界上交出这个状态的所有权。
从表面上看,这个操作与「共享内存系统」中执行的通过加锁实现原子更新操作相同,但从底层实现上看则不同:一个对同一个内存地址持有的值进行操作,一个是从消息通道读取数据并处理。由于需要执行状态复制操作,所以大多数消息传递的实现在性能上并不优越,但线程中的状态管理工作则会变得更加简单,不过鱼和熊掌不可兼得,如果想让编码简单,性能就要做牺牲,如果想追求性能,代码编写起来就比较费劲,这也是我们为什么通常不会直接通过事件驱动的异步 IO 来实现并发编程一样,因为这涉及到直接调用操作系统底层的库函数(select、epoll、libevent 等)来实现,非常复杂。
注:最早被广泛应用的「消息传递系统」是由 C. A. R. Hoare 在他的 Communicating Sequential Processes 中提出的,在 CSP 系统中,所有的并发操作都是通过独立线程以异步运行的方式来实现的。这些线程必须通过在彼此之间发送消息,从而向另一个线程请求信息或者将信息提供给另一个线程。
Go 语言协程支持
与传统的系统级线程和进程相比,协程的最大优势在于轻量级(可以看作用户态的轻量级线程),我们可以轻松创建上百万个协程而不会导致系统资源衰竭,而线程和进程通常最多也不能超过 1 万个(C10K问题)。多数语言在语法层面并不直接支持协程,而是通过库的方式支持,比如 PHP 的 Swoole 扩展库,但用库的方式支持的功能通常并不完整,比如仅仅提供轻量级线程的创建、销毁与切换等能力。如果在这样的轻量级线程中调用一个同步 IO 操作,比如网络通信、本地文件读写,都会阻塞其他的并发执行轻量级线程,从而无法真正达到轻量级线程本身期望达到的目标。
Go 语言在语言级别支持协程,称之为 goroutine。Go 语言标准库提供的所有系统调用操作(当然也包括所有同步 IO 操作),都有协程的身影。协程间的切换管理不依赖于系统的线程和进程,也不依赖于 CPU 的核心数量,这让我们在 Go 语言中通过协程实现并发编程变得非常简单。
Go 语言的协程系统是基于「消息传递系统」实现的,在 Go 语言的编程哲学中,创始人 Rob Pike 推介「Don’t communicate by sharing memory, share memory by communicating(不要通过共享内存来通信,而应该通过通信来共享内存)」,这正是「消息传递系统」的精髓所在。Go 语言中的 goroutine 和用于传递协程间消息的 channel 一起,共同构筑了 Go 语言协程系统的基石。摆脱了所有历史包袱的 Go 协程,让并发编程从未如此简单好用。
后续教程将详细为你介绍 Go 语言如何通过协程实现并发编程。