Appearance
Scrapy-Redis 使用布隆过滤器
在一些新闻APP中,如何做到每次推荐给该用户的内容不会重复,过滤已经看过的内容呢?
一般都会想到只要记录了每个用户看过的历史记录,每次推荐的时候去查询数据库过滤存在的数据实现去重,实际上如果历史记录存储在关系数据库里,去重就需要频繁的对数据库进行 exists 查询,当系统并发量很高时,数据库是很难扛住压力的。
那么有人说了,可以使用缓存,把历史数据都存在 Redis 中,但是当历史记录达到一定量级后,又会发现内存空间压力扛不住了。
所以我们可以考虑使用布隆过滤器去解决这种去重问题,又快又省内存,在很多互联网产品开发中,是一把利器。
布隆过滤器
简介
布隆过滤器(Bloom Filter)是由 1970 年布隆提出来的,它实际上是一个很长的二进制向量和一系列随机映射函数的实现。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好得多,缺点是有一定的误识别率和删除困难。
原理
当你往简单数组或列表中插入新数据时,将不会根据插入项的值来确定该插入项的索引值,这意味着新插入项的索引值与数据值之间没有之间关系,这样的话,当你需要在数组或列表中搜索相应值的时候,你必须遍历已有的集合,若集合中存在大量的数据,就会影响数据查找的效率。
针对这个问题,你可以考虑使用哈希表,利用哈希表你可以通过对“值”进行哈希处理来获得该值的键或索引值,然后把该值存放到对应的索引位置,这意味着索引值是由插入项的值所确定的,当你需要判断列表中是否存在该值时,只需要对值进行哈希处理并在相应的索引位置进行搜索即可,这时的搜索速度是非常快的。
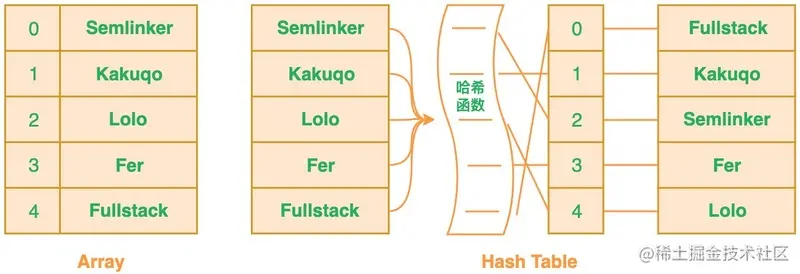
根据定义,布隆过滤器可以检查值是 “可能在集合中” 还是 “绝对不在集合中”。“可能”表示有一定的概率,也就是说可能存在一定的误判率。那为什么会误判呢?下面我们来分析下具体的原因。
布隆过滤器(Bloom Filter)本质上是由长度为 m 的向量位或位列表(仅包含 0 或 1 位值的列表)组成,最初所有的值均设置为 0,如下图所示:

为了将数据项添加到布隆过滤器中,我们会提供 K 个不同的哈希函数,并将结果位置上对应位的值置为 “1”。在前面所提到的哈希表中,我们使用的是单个哈希函数,因此只能输出单个索引值。而对于布隆过滤器来说,我们将使用多个哈希函数,这将会产生多个索引值。
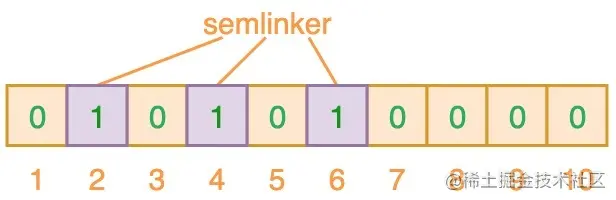
如上图所示,当输入 “semlinker” 时,预设的 3 个哈希函数将输出 2、4、6,我们把相应位置 1。假设另一个输入 ”kakuqo“,哈希函数输出 3、4 和 7。你可能已经注意到,索引位 4 已经被先前的 “semlinker” 标记了。此时,我们已经使用 “semlinker” 和 ”kakuqo“ 两个输入值,填充了位向量。当前位向量的标记状态为:
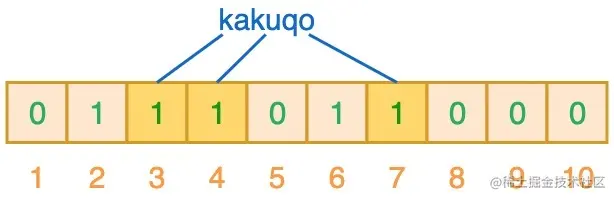
当对值进行搜索时,与哈希表类似,我们将使用 3 个哈希函数对 ”搜索的值“ 进行哈希运算,并查看其生成的索引值。假设,当我们搜索 ”fullstack“ 时,3 个哈希函数输出的 3 个索引值分别是 2、3 和 7:
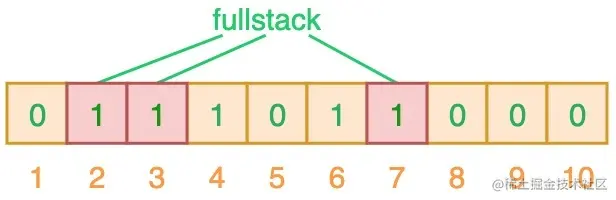
从上图可以看出,相应的索引位都被置为 1,这意味着我们可以说 ”fullstack“ 可能已经插入到集合中。事实上这是误报的情形,产生的原因是由于哈希碰撞导致的巧合而将不同的元素存储在相同的比特位上。幸运的是,布隆过滤器有一个可预测的误判率(FPP):
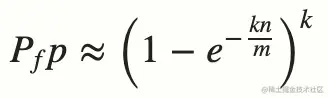
- n 是已经添加元素的数量;
- k 哈希的次数;
- m 布隆过滤器的长度(如比特数组的大小);
极端情况下,当布隆过滤器没有空闲空间时(满),每一次查询都会返回 true 。这也就意味着 m 的选择取决于期望预计添加元素的数量 n ,并且 m 需要远远大于 n 。
实际情况中,布隆过滤器的长度 m 可以根据给定的误判率(FFP)的和期望添加的元素个数 n 的通过如下公式计算:
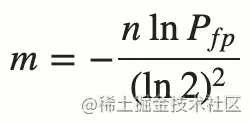
了解完上述的内容之后,我们可以得出一个结论,当我们搜索一个值的时候,若该值经过 K 个哈希函数运算后的任何一个索引位为 ”0“,那么该值肯定不在集合中。但如果所有哈希索引值均为 ”1“,则只能说该搜索的值可能存在集合中。
关于 M(过滤器长度)、K(哈希次数)、P(误判率)的计算应用
题目
不安全网页的黑名单包含100亿个黑名单网页,每个网页的URL最多占用64字节。现在想要实现一种网页过滤系统,可以根据网页的URL判断该网站是否在黑名单上,请设计该系统。要求该系统允许有万分之一以下的判断失误率,并且使用的额外空间不要超过30G。
需求
布隆过滤器的bitarray大小如何确定?
分析
设bitarray大小为m,样本数量为n,失误率为p。 由题可知 n = 100亿,p = 0.01% 单个样本大小不影响布隆过滤器大小,因为样本会通过哈希函数得到输出值。 使用样本数量n和失误率p可以算出m,公式为:
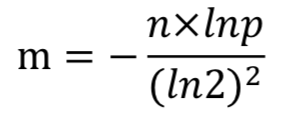
求得 m = 19.19n,向上取整为 20n。所以2000亿bit,约为25G。 # 1GB=1024MB 1MB=1024KB 1KB=1024Byte 1Byte=8bit 所使用哈希函数个数k可以由以下公式求得:
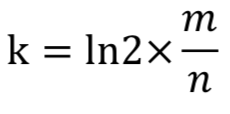
ln2约等于0.7也就是最优k值 所以 k = 14,即需要14个哈希函数。 通过 m = 20n, k = 14,可以通过以下公式算出设计的布隆过滤器的真实失误率为0.006%。 # 也就是当k值越接近0.7*m/n的值时,误判概率越小
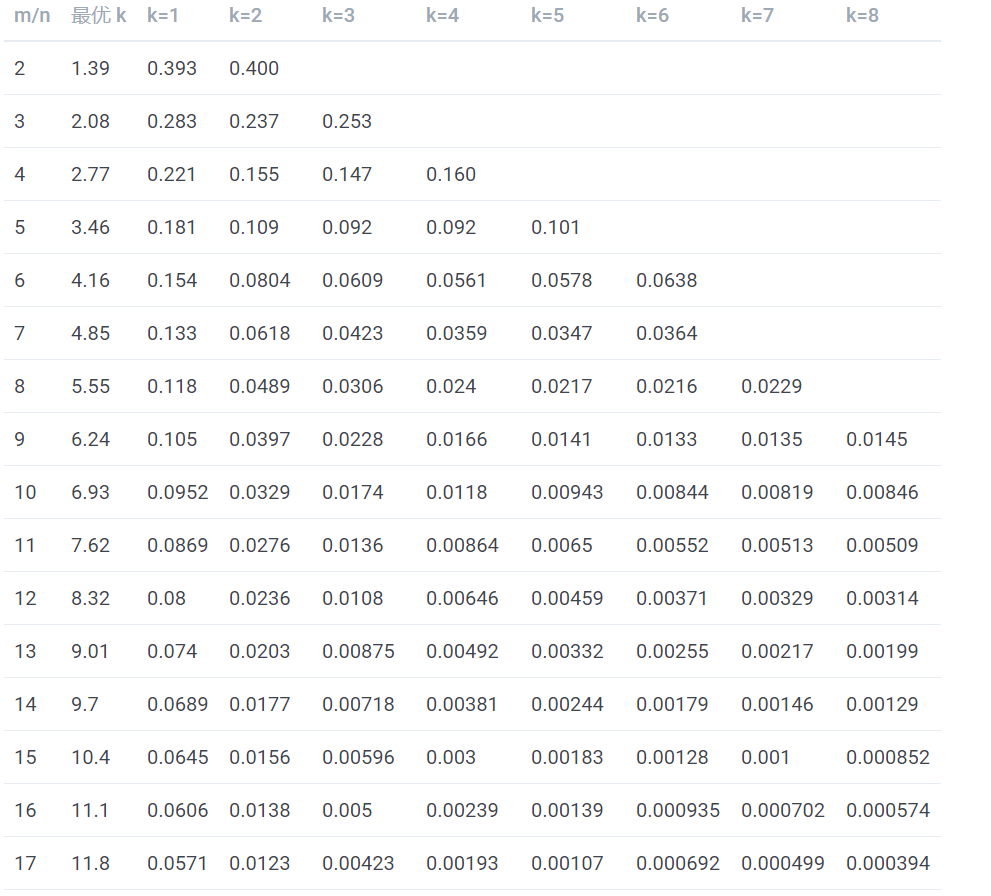
表中第一列为 m/n 的值,第二列为最优 k 值,其后列为不同 k 值的误判概率,可以看到当 k 值确定时,随着 m/n 的增大,误判概率逐渐变小。当 m/n 的值确定时,当 k 越靠近最优 K 值,误判概率越小。另外误判概率总体来看都是极小的,在容忍此误判概率的情况下,大幅减小存储空间和判定速度是完全值得的
优缺点
优点:
- 空间效率高、所占空间小
- 查询时间短
缺点:
- 元素添加到集合中后,不能被删除
- 有一定的误判率
应用场景
在实际工作中,布隆过滤器常见的应用场景如下:
- 网页爬虫对 URL 去重,避免爬取相同的 URL 地址;
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱;
- Google Chrome 使用布隆过滤器识别恶意 URL;
- Medium 使用布隆过滤器避免推荐给用户已经读过的文章;
- Google BigTable,Apache HBbase 和 Apache Cassandra 使用布隆过滤器减少对不存在的行和列的查找。 除了上述的应用场景之外,布隆过滤器还有一个应用场景就是解决缓存穿透的问题。所谓的缓存穿透就是服务调用方每次都是查询不在缓存中的数据,这样每次服务调用都会到数据库中进行查询,如果这类请求比较多的话,就会导致数据库压力增大,这样缓存就失去了意义。
利用布隆过滤器我们可以预先把数据查询的主键,比如用户 ID 或文章 ID 缓存到过滤器中。当根据 ID 进行数据查询的时候,我们先判断该 ID 是否存在,若存在的话,则进行下一步处理。若不存在的话,直接返回,这样就不会触发后续的数据库查询。需要注意的是缓存穿透不能完全解决,我们只能将其控制在一个可以容忍的范围内。
动手实现布隆过滤器
根据布隆过滤器的原理,来用 Python 手动实现一个布隆过滤器。 首先需要安装 mmh3,mmh3是 MurmurHash3 算法的实现,Redis 中也是采用此hash算法。然后还需要安装 bitarray,Python 中位数组的实现。
安装所需要的包
pip install mmh3
pip install bitarray
环境准备后,开始实现一个简单的布隆过滤器,代码如下:
Python
# 定义 SimpleBloomFilter 类
class SimpleBloomFilter(object):
""" 简单的布隆过滤器实现 """
def __init__(self, bit_size=10000, hash_count=3, start_seed=41):
# 初始化布隆过滤器的位数组大小
self.bit_size = bit_size
# 初始化哈希函数的数量
self.hash_count = hash_count
# 初始化哈希函数的种子值
self.start_seed = start_seed
# 初始化位数组
self.initialize()
# 初始化位数组
def initialize(self):
# 使用 bitarray 库初始化位数组
self.bit_array = bitarray(self.bit_size)
# 将位数组的所有位都设置为 0
self.bit_array.setall(0)
# 向布隆过滤器中添加数据
def add(self, data):
# 获取数据对应的哈希值在位数组中的位置
bit_points = self.get_hash_points(data)
# 将这些位置上的位都设置为 1
for index in bit_points:
self.bit_array[index] = 1
# 判断数据是否在布隆过滤器中
def is_contain(self, data):
# 获取数据对应的哈希值在位数组中的位置
bit_points = self.get_hash_points(data)
# 获取这些位置上的位的值,并组成列表
result = [self.bit_array[index] for index in bit_points]
# 如果所有位置上的位的值都为 1,则说明数据可能在布隆过滤器中
return all(result)
# 计算数据在位数组中的哈希值所在的位置
def get_hash_points(self, data):
return [
mmh3.hash(data, index) % self.bit_size
for index in range(self.start_seed, self.start_seed + self.hash_count)
]
上述代码每行都写了注释,可以仔细阅读下,测试代码如下:
Python
bloom_filter = SimpleBloomFilter(bit_size=10000, hash_count=6)
bloom_filter.add('python')
bloom_filter.add('scrapy')
print(bloom_filter.is_contain('python'))
print(bloom_filter.is_contain('scrapy'))
print(bloom_filter.is_contain('scrapy-redis'))
输出结果
True
True
False
这样就实现了一个简单的布隆过滤器,但是在实际生产环境中,存储的量级非常大,通常采集 Redis 的 bitmap 数据结构来代替自己实现的位数组。
第三方库实现布隆过滤器(不包含Redis)
在 Python 强大的支持库中,有很多实现了布隆过滤器的库,这里使用 pybloom_live 来做演示
pybloom_live 依赖 bitarray ,所以要确保已经安装 bitarray
安装 pybloom_live
pip install pybloom_live
固定长度的过滤器
Python
# 导入 pybloom_live 库中的布隆过滤器类
from pybloom_live import BloomFilter
# 定义两个 URL 地址
url1 = 'https://www.baidu.com'
url2 = 'https://www.qq.com'
# 创建一个容量为 1000 的布隆过滤器对象
bf = BloomFilter(capacity=1000)
# 将 url1 添加到布隆过滤器中
bf.add(url1)
# 判断 url1 是否在布隆过滤器中,输出 Trueprint(url1 in bf)
# 判断 url2 是否在布隆过滤器中,输出 Falseprint(url2 in bf)
长度可扩容的过滤器
Python
# 导入 pybloom_live 库中的 ScalableBloomFilter 类
from pybloom_live import ScalableBloomFilter
# 创建一个初始容量为 100,错误率为 0.001 的可扩展布隆过滤器对象
bf = ScalableBloomFilter(initial_capacity=100, error_rate=0.001)
# 定义两个 URL 地址
url1 = 'https://www.baidu.com'
url2 = 'https://www.qq.com'
# 将 url1 添加到可扩展布隆过滤器中
bf.add(url1)
# 判断 url1 是否在可扩展布隆过滤器中,输出 True
print(url1 in bf)
# 判断 url2 是否在可扩展布隆过滤器中,输出 False
print(url2 in bf)
原生语言 + Redis 实现布隆过滤器
在上面手动实现了一个简单的布隆过滤器中讲到如果当数据达到一定量级,内存压力是相当大的,所以就可以考虑结合 Redis 中的 bitmap 来实现,每种语言应该都会有对应写好的包,例如 Java 的话,可以选择 JReBloom。
这里用 Python 演示
Python
import mmh3 # 导入 mmh3 库,用于生成哈希值
import redis # 导入 redis 库,用于实现分布式的缓存系统
class SimpleBloomFilterBitmap(object):
""" 集合 Redis 中的 bitmap 来实现一个简单的布隆过滤器 """
def __init__(self, bf_key, bit_size=10000, hash_count=3, start_seed=41):
"""
初始化布隆过滤器对象
:param bf_key: 用于在 Redis 中存储数据的 key
:param bit_size: bitmap 的长度(默认为 10000)
:param hash_count: 哈希函数的个数(默认为 3)
:param start_seed: 哈希函数的种子值(默认为 41)
"""
self.bf_key = bf_key
self.bit_size = bit_size
self.hash_count = hash_count
self.start_seed = start_seed
self.client = redis.StrictRedis(host='127.0.0.1') # 连接 Redis 客户端
def add(self, data):
"""
将数据添加到布隆过滤器中
:param data: 待添加的数据
"""
bit_points = self._get_hash_points(data) # 获取数据对应的 bitmap 索引
for index in bit_points:
self.client.setbit(self.bf_key, index, 1) # 将 bitmap 对应位置置为 1
def madd(self, mdata):
"""
将多个数据添加到布隆过滤器中
:param mdata: 待添加的数据,可以是单个数据或数据列表
"""
if isinstance(mdata, list):
for data in mdata:
self.add(data)
else:
self.add(mdata)
def exists(self, data):
"""
判断数据是否在布隆过滤器中
:param data: 待查询的数据
:return: 若数据可能在布隆过滤器中,则返回 True,否则返回 False
"""
bit_points = self._get_hash_points(data) # 获取数据对应的 bitmap 索引
result = [
self.client.getbit(self.bf_key, index) for index in bit_points # 获取 bitmap 对应位置的值
]
return all(result) # 若 bitmap 的对应位置都为 1,则返回 True,否则返回 False
def mexists(self, mdata):
"""
判断多个数据是否在布隆过滤器中
:param mdata: 待查询的数据,可以是单个数据或数据列表
:return: 包含数据及其是否在布隆过滤器中的字典
"""
result = {}
if isinstance(mdata, list):
for data in mdata:
result[data] = self.exists(data)
else:
result[mdata] = mdata
return result
def _get_hash_points(self, data):
"""
用 mmh3 哈希算法,对数据进行 hash_count 次哈希,产生多个哈希值
并对每个哈希值取余,得到该哈希值在 bitmap 中的索引位置
:param data: 待哈希的数据
:return: 数据对应的 bitmap 索引列表
"""
return [
mmh3.hash(data, index) % self.bit_size
for index in range(self.start_seed, self.start_seed + self.hash_count)
]
测试代码如下:
Python
if __name__ == '__main__':
# 创建 SimpleBloomFilterBitmap 对象,并指定 Redis key 为 'bf_test' bloom_filter_bitmap = SimpleBloomFilterBitmap(bf_key='bf_test')
# 添加数据 'test01' 到布隆过滤器中
bloom_filter_bitmap.add('test01')
# 添加数据 'test02' 到布隆过滤器中
bloom_filter_bitmap.add('test02')
# 批量添加数据 ['test03', 'test04'] 到布隆过滤器中
bloom_filter_bitmap.madd(['test03', 'test04'])
# 检查数据 'test01' 是否在布隆过滤器中
print(bloom_filter_bitmap.exists('test01'))
# 检查数据 'test02' 是否在布隆过滤器中
print(bloom_filter_bitmap.exists('test02'))
# 批量检查数据 ['test01', 'test03', 'test04', 'test08', 'test09'] 是否在布隆过滤器中
print(bloom_filter_bitmap.mexists(['test01', 'test03', 'test04', 'test08', 'test09']))
输出结果
True
True
{'test01': True, 'test03': True, 'test04': True, 'test08': False, 'test09': False}
Redis-BloomFilter 实践
Redis在4.0版本推出了 module 的形式,可以将 module 作为插件额外实现Redis的一些功能。官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module。
传统 Redis 安装 RedisBloom 插件
推荐使用 Redis 版本 6.x,最低 4.x 来集成布隆过滤器。如下指令查看版本。
在 redis-cli 中输入 info
redis_version: xxx 即为版本号
下载插件源码:https://github.com/RedisBloom/RedisBloom/tags
解压文件
tar -zxvf RedisBloom-2.4.5.tar
编译插件
cd RedisBloom-2.4.5
make
编译成功,会看到 redisbloom.so 文件
修改 redis.conf 配置文件,新增 loadmodule 项,并重启 redis
loadmodule /opt/app/RedisBloom-2.4.5/redisbloom.so
指定配置文件并启动 Redis
redis-server /opt/app/redis-6.2.6/redis.conf
加载成功的页面如下:

直接安装 RedisBloom 使用
如果还没有安装过 Redis,可以考虑直接使用 Docker 的方式来安装,安装步骤如下:
1. docker pull redislabs/rebloom:latest
2. docker run -d -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
3. docker exec -it redis-redisbloom /bin/bash
RedisBloom 相关操作
RedisBloom 相关操作如下:
- reserve
- add,madd
- exists,mexists
- info
详细的用法如下:
reserve
bf.reserve {key} {error_rate}{initial_size} [EXPANSION {expansion}] [NONSCALING]
创建一个空的名为 key 的布隆过滤器,并设置一个期望的错误率和初始大小。{error_rate} 过滤器的错误率在0-1之间。
- key:filter 的名字。
- error_rate:期望的错误率,默认 0.1,值越低,需要的空间越大。
- capacity:初始容量,默认 100,当实际元素的数量超过这个初始化容量时,误判率上升。
- EXPANSION:可选参数,当添加到布隆过滤器中的数据达到初始容量后,布隆过滤器会自动创建一个子过滤器,子过滤器的大小是上一个过滤器大小乘以 expansion;expansion 的默认值是 2,也就是说布隆过滤器扩容默认是 2 倍扩容。
- NONSCALING:可选参数,设置此项后,当添加到布隆过滤器中的数据达到初始容量后,不会扩容过滤器,并且会抛出异常 ((error) ERR non scaling filter is full) 说明:BloomFilter 的扩容是通过增加 BloomFilter 的层数来完成的。每增加一层,在查询的时候就可能会遍历多层 BloomFilter 来完成,每一层的容量都是上一层的两倍(默认)。
如果不使用 bf.reserve 命令创建,而是使用 Redis 自动创建的布隆过滤器,默认的 error_rate 是 0.01,capacity是 100。
布隆过滤器的 error_rate 越小,需要的存储空间就越大,对于不需要过于精确的场景,error_rate 设置稍大一点也可以。
布隆过滤器的 capacity 设置的过大,会浪费存储空间,设置的过小,就会影响准确率,所以在使用之前一定要尽可能地精确估计好元素数量,还需要加上一定的冗余空间以避免实际元素可能会意外高出设置值很多。
如果想要布隆过滤器知道具体的耗费内存大小以及对应的错误率的信息, 可以使用查看这个布隆过滤器计算器
127.0.0.1:6379> bf.reserve bf_demo 0.001 1000
OK
add,madd
bf.add {key} {item} bf.madd {key} {item} [item…]
添加单个数据
127.0.0.1:6379> bf.add bf_demo d1
(integer) 1
127.0.0.1:6379> bf.add bf_demo d2
(integer) 1
127.0.0.1:6379> bf.add bf_demo d3
(integer) 1
127.0.0.1:6379> bf.add bf_demo d1
(integer) 0 因为 key 为 bf_demo 中已经存在 d1,所以返回 0
添加多个数据
127.0.0.1:6379> bf.madd bf_demo d4 d5 d6
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:6379> bf.madd bf_demo d7 d8 d9 d4
1) (integer) 1
2) (integer) 1
3) (integer) 1
4) (integer) 0 因为 key 为 bf_demo 中已经存在 d1,所以返回 0
往过滤器中添加元素。如果key不存在,过滤器会自动创建。
exists,mexists
bf.exists {key} {item} bf.mexists {key} {item} [item…]
判断过滤器中是否存在该元素,不存在返回0,存在返回1。
查询单个数据是否存在
127.0.0.1:6379> bf.exists bf_demo d2
(integer) 1
127.0.0.1:6379> bf.exists bf_demo d3
(integer) 1
127.0.0.1:6379> bf.exists bf_demo d100 不存在则返回 0
(integer) 0
查询多个数据是否存在
127.0.0.1:6379> bf.mexists df_demo d1 d2 d3 d100 d200 d300
1) (integer) 1
2) (integer) 1
3) (integer) 1
4) (integer) 0
5) (integer) 0
6) (integer) 0
info
查看创建过的布隆过滤器信息
127.0.0.1:6379> bf.info bf_demo
1) Capacity
2) (integer) 1000
3) Size
4) (integer) 2136
5) Number of filters
6) (integer) 1
7) Number of items inserted
8) (integer) 9
9) Expansion rate
10) (integer) 2
返回值:
- Capacity:预设容量。
- Size:实际占用情况,但如何计算待进一步确认。
- Number of filters:过滤器层数。
- Number of items inserted:已经实际插入的元素数量。
- Expansion rate:子过滤器扩容系数(默认 2)。
用 Python 代码实现
官方提供了一个包 redisbloom,下方是官方例子
Python
# 导入 redisbloom 的客户端类 Client
from redisbloom.client import Client
# 创建一个 Client 实例,连接 Redis 数据库的地址为 '127.0.0.1',端口为 6379
rb = Client(host='127.0.0.1', port=6379)
# 在 Redis 的 Bloom Filter 中添加两个元素 'baidu' 和 'google',过滤器的名称为 'urls'
rb.bfAdd('urls', 'baidu')
rb.bfAdd('urls', 'google')
# 判断 'baidu' 是否在名为 'urls' 的 Bloom Filter 中,返回值为 True(1)
print(rb.bfExists('urls', 'baidu')) # out: 1
# 判断 'tencent' 是否在名为 'urls' 的 Bloom Filter 中,返回值为 False(0)
print(rb.bfExists('urls', 'tencent')) # out: 0
# 在名为 'urls' 的 Bloom Filter 中添加两个元素 'a' 和 'b'
rb.bfMAdd('urls', 'a', 'b')
# 判断多个元素是否在名为 'urls' 的 Bloom Filter 中,返回值为列表 [1, 1, 0],分别表示 'google'、'baidu'、'tencent' 是否在 Bloom Filter 中
print(rb.bfMExists('urls', 'google', 'baidu', 'tencent')) # out: [1, 1, 0]
扩展学习
RedisBloom 模块 还实现了 布谷鸟过滤器,简单了解了一下,有一篇论文有兴趣的通信可以读一下 www.cs.cmu.edu/~dga/papers…
文章中对比了布隆过滤器和布谷鸟过滤器,相比布谷鸟过滤器,布隆过滤器有以下不足:
- 查询性能弱 查询性能弱是因为布隆过滤器需要使用N个 hash函数计算位数组中N个不同的点,这些点在内存上跨度较大,会导致CPU缓存命中率低。
- 空间利用效率低 在相同的误判率下,布谷鸟的空间利用率要高于布隆过滤器,能节省40%左右。
- 不支持删除操作 这是布谷鸟过滤器相对布隆过滤器最大的优化,支持反向操作,删除功能。
- 不支持计数
因暂时未对布谷鸟过滤器进行比较深入的了解,不清楚到底是不是文章说的那么好,有时间再研究一下。
Scrapy-Redis 使用布隆过滤器
Scrapy-Redis 默认是有去重机制的,Scrapy-Redis 将 Request 的指纹存储到了 Redis 集合中,每个指纹的长度为 40,例如 27adcc2e8979cdee0c9cecbbe8bf8ff51edefb61 就是一个指纹,它的每一位都是 16 进制数。 计算一下用这种方式耗费的存储空间。每个十六进制数占用 4 b,1 个指纹用 40 个十六进制数表示,占用空间为 20 B,1 万个指纹即占用空间 200 KB,1 亿个指纹占用 2 GB。当爬取数量达到上亿级别时,Redis 的占用的内存就会变得很大,而且这仅仅是指纹的存储。Redis 还存储了爬取队列,内存占用会进一步提高,更别说有多个 Scrapy 项目同时爬取的情况了。当爬取达到亿级别规模时,Scrapy-Redis 提供的集合去重已经不能满足我们的要求。所以我们需要使用一个更加节省内存的去重算法 Bloom Filter。
使用 原生语言 + Redis 实现
基于原生语言 + Redis 已经有前辈写好的第三方库 scrapyRedisBloomFilter,这个库的实现原理则为本文中 原生语言 + Redis 实现布隆过滤器 中讲到的那样,具体可以查看仓库代码,下面说下如何使用:
安装库
pip install scrapy-redis-bloomfilter
修改 settings.py 配置文件
Python
# 如果你的 scrapy_redis 版本是 <= 0.7.1,请使用这个调度器
SCHEDULER = "scrapy_redis_bloomfilter.scheduler.Scheduler"
# 通过 redis 确保所有爬虫使用相同的去重过滤器
DUPEFILTER_CLASS = "scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter"
# Redis 数据库的 URL 地址
REDIS_URL = 'redis://localhost:6379'
# 使用的哈希函数数量,默认为 6
BLOOMFILTER_HASH_NUMBER = 6
# Bloom 过滤器使用的内存位数,30 表示使用 2^30 = 128MB 内存,默认为 10
BLOOMFILTER_BIT = 10
# 是否持久化
SCHEDULER_PERSIST = True
基于 Redis-BloomFilter 实现
基于 Redis-BloomFilter 也有第三方库实现了 scrapy_redis_bf,这个库取消了由自己通过哈希函数和位数组的方式实现布隆过滤器,而是直接采用了 Redis 支持的 BloomFilter 插件,减少了与 Redis 之间的网络交互次数,效率要好上一些。
需要提前使 Redis 支持 BloomFilter
安装库
pip install scrapy-redis-bf
修改 settings.py 配置文件
Python
SCHEDULER = "scrapy_redis_bf.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis_bf.dupefilter.RFPDupeFilter"
# 默认是通过spider的name来创建redis key
SCHEDULER_DUPEFILTER_ATTR = "name"
# 格式:redis://[:password@]host[:port][/database][?[timeout=timeout[d|h|m|s|ms|us|ns]][&database=database]]
REDIS_URL = 'redis://localhost:6379'
# 错误率
BLOOMFILTER_ERRORRATE = 0.001
# 去重量
BLOOMFILTER_CAPACITY = 10000
参考文章
[1] https://www.51cto.com/article/704389.html
[2] https://juejin.cn/post/6844904007790673933
[3] https://juejin.cn/post/6844903862072000526
[4] https://www.cnblogs.com/yscl/p/12003359.html
[5] https://www.cnblogs.com/tangjian219/articles/12344327.html
[6] https://blog.csdn.net/Qwertyuiop2016/article/details/127103954